
|
|
|
|
|
Banco de datos del español
Manual de consulta
Versión HTML 2.0
1. INTRODUCCIÓN.
*2. REQUISITOS DEL SISTEMA.
*3. LA INTERFAZ DE CONSULTA.
*3.1 DESCRIPCIÓN.
*3.1.1 Inicio de la sesión de consulta.
*3.1.2 Finalización de la sesión.
*3.1.3 Manejo de la interfaz gráfica.
*3.2 SELECCIÓN DE CORPUS.
*3.3 CRITERIOS RESTRICTIVOS.
*3.3.1 Selección de medio.
*3.3.2 Selección de autor.
*3.3.3 Selección de obra.
*3.3.4 Criterio cronológico.
*3.3.5 Criterio temático.
*3.3.6 Criterio geográfico.
*3.4 SINTAXIS DEL LENGUAJE DE CONSULTA.
*3.4.1 Normas generales.
*3.4.2 Consultas simples.
*3.4.3 Expresiones lógicas.
*3.4.4 Comodines.
*3.4.5 Filtros.
*3.4.6 Reducción del número de documentos.
*3.4.7 Reducción del número de ejemplos.
*4. VISUALIZACIÓN Y CLASIFICACIÓN DE LOS EJEMPLOS.
*4.1 AUTORES Y OBRAS.
*4.2 CONCORDANCIAS.
*4.2.1 Clasificación.
*4.2.2 Clasificación múltiple.
*4.2.3 Agrupaciones.
*4.2.3 Selección manual de ejemplos.
*4.2.4 Visualización de la información codificada.
*5. PRESENTACIÓN ESTADÍSTICA DE LOS DATOS.
*6. EXPORTACIÓN E IMPRESIÓN DE LOS RESULTADOS DE LAS CONSULTAS.
*7. UN EJEMPLO PRÁCTICO.
*8. LIMITACIONES Y PROBLEMAS CONOCIDOS.
*8.1 LIMITACIONES DEL SISTEMA.
*8.2 PROBLEMAS MÁS FRECUENTES.
*9. DESARROLLOS EN CURSO.
*10. CONSULTAS Y SUGERENCIAS.
*11. CÓMO CITAR EL CORPUS.
*APÉNDICE 1. DISEÑO Y ESTRUCTURA DEL BANCO DE DATOS DEL ESPAÑOL.
*A1.1 DISEÑO DEL CORPUS DE REFERENCIA DEL ESPAÑOL ACTUAL. CREA.
*A1.2 DISEÑO DEL CORPUS DIACRÓNICO DEL ESPAÑOL. CORDE.
*Este documento describe las posibilidades del programa informático de consulta del Banco de Datos del Español de la Real Academia Española. Se trata de un texto para personas sin conocimientos específicos de la materia, en el que se proporcionan las nociones básicas para la consulta interactiva del mayor recurso léxico -más de 200 millones de palabras- disponible para el idioma español.
El sistema de consulta es accesible desde cualquier ordenador conectado a la Red Internet que disponga de las siguientes características:
- Navegador WWW.
- Resolución gráfica de la pantalla de 640x480 (VGA) (Es aconsejable 800x600 (SVGA)).
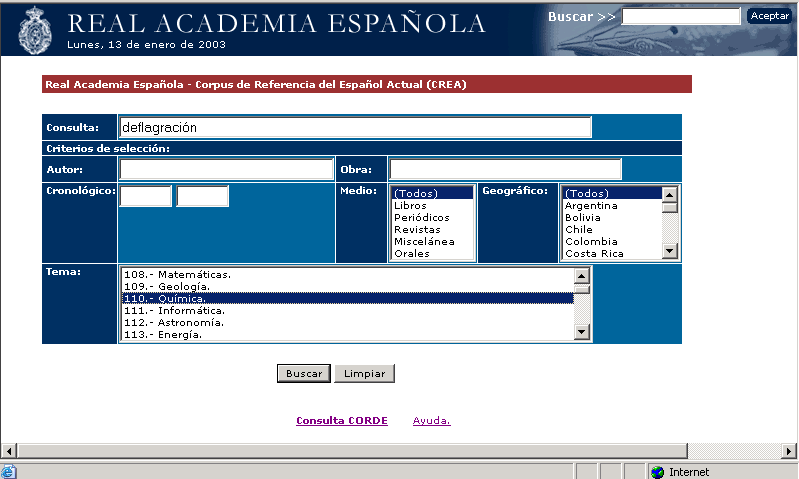
El sistema de consulta (fig. 1) cuenta con tres ventanas principales. La primera de ellas se ocupa de la construcción del perfil de consulta. Para ello, dispone de un apartado destinado a la redacción de la consulta, y de diversos criterios selectivos que facilitan la selección dinámica de subconjuntos documentales del corpus.
Fig. 1. Ventana principal. Creación del perfil de consulta.
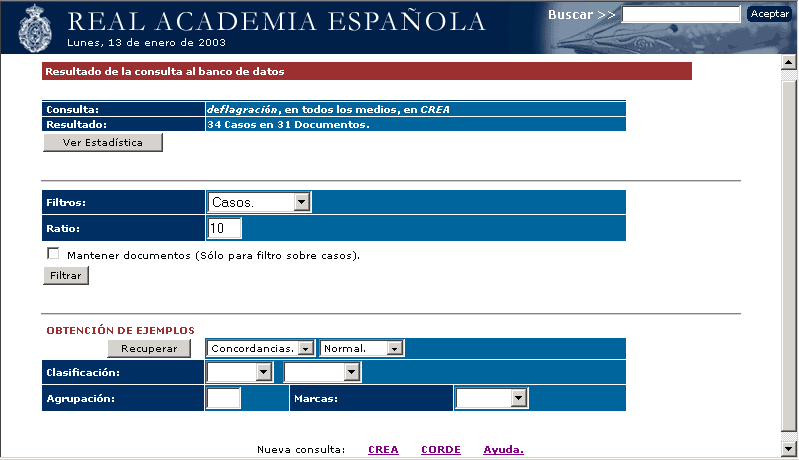
La segunda ventana (Fig. 2) (Resultados) ofrece datos estadísticos de la consulta realizada, y la posibilidad de establecer filtros de reducción de documentos y/o ejemplos, en el caso de que el número de ellos sobrepase los límites prefijados, o resulte excesivo para el propósito del consultante.
Fig. 2. Ventana de resultados.
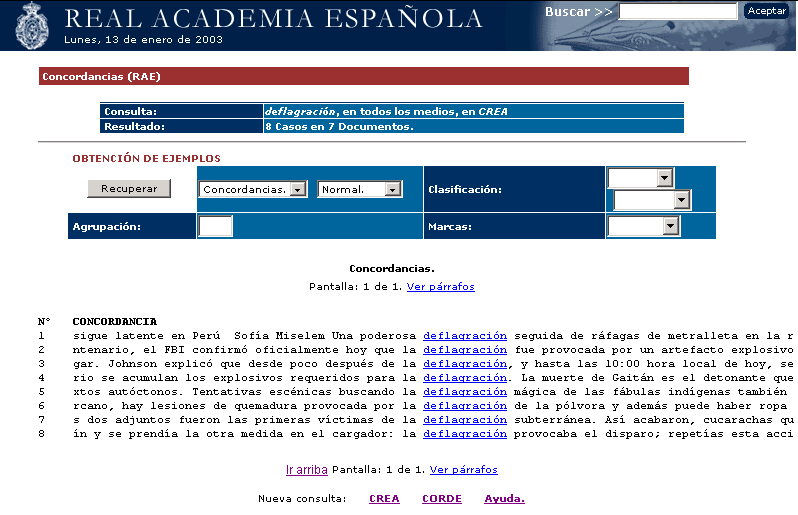
En la ventana de (Concordancias)(fig.3) se muestra la descripción bibliográfica de los documentos relacionados con la consulta, o bien los ejemplos propiamente dichos, dependiendo de la opción seleccionada en la ventana anterior. En ella es posible también obtener diversas clasificaciones de los datos, así como vistas ampliadas que pueden mostrar la información relativa a la codificación.
Fig. 3. Visualización de los ejemplos.
3.1.1 Inicio de la sesión de consulta.
La interfaz de consulta se inicia desde el enlace establecido al efecto en la página WWW de la RAE (https://www.rae.es). Es posible iniciar varias sesiones simultáneas del programa sin más requisito que la apertura de varias páginas del navegador WWW. Para recuperar una sesión cancelada accidentalmente basta retroceder a la página de carga mediante los botones del navegador WWW.
3.1.2 Finalización de la sesión.
La sesión de consulta finaliza pulsando con el ratón el aspa [X] situada en la esquina superior derecha de la pantalla.
3.1.3 Manejo de la interfaz gráfica.
El sistema está construido para ser manejado mediante el uso del ratón o puntero electrónico, sin embargo, es posible recurrir a los tabuladores y a la barra espaciadora para realizar los desplazamientos entre campos y la selección de opciones. Análogamente a cualquier entorno de ventanas gráficas, basta con situar el cursor sobre la zona deseada y efectuar una pulsación sobre el mismo. No obstante, en algunos casos, el sistema difiere del habitual:
Ventana de ampliación de contexto. En la ventana correspondiente a las concordancias es posible ampliar el contexto desplegando ventanas auxiliares. Para ello, basta situar el ratón sobre la palabra resaltada de la concordancia deseada y efectuar una pulsación.
Limpieza de ventanas. En la ventana de consulta existe un botón de limpieza general que restaura la ventana a su aspecto original.
Barras de desplazamiento. En las ventanas cuyo contenido sobrepasa el espacio disponible en la pantalla, es posible efectuar desplazamientos verticales u horizontales mediante la pulsación sostenida y arrastre del ratón sobre las barras de desplazamiento correspondientes. En el caso de las ventanas de documentos y concordancias, resulta obligado recurrir a dicha técnica para ver la información completa.
Selección múltiple. En algunas ventanas es posible seleccionar más de una opción. Para ello, basta con pulsar simultáneamente la tecla de Control y el botón izquierdo del ratón.
El banco de datos del español está dividido en dos grandes conjuntos documentales: CREA y CORDE. El CREA (Corpus de Referencia del Español Actual) contiene ejemplos de los últimos 25 años del idioma. El CORDE (Corpus Diacrónico del Español) abarca ejemplos desde los orígenes del español hasta el limite cronológico con el CREA.
La selección inicial del corpus dependerá del enlace elegido. No obstante, existe en la zona inferior de la ventana de consulta un enlace que facilita el cambio a posteriori.
Es posible establecer ciertos criterios restrictivos previos a la consulta. En lugar de establecer divisiones a priori, el sistema permite construir restricciones dinámicas, es decir, ofrece la posibilidad de configurar "subcorpus virtuales" a la medida requerida.
La ventana principal de la interfaz de consulta contiene los elementos que configuran el sistema de selección. Mediante la libre combinación de dichos elementos, es posible construir perfiles de consulta que actuarán sobre la totalidad de los datos del Corpus elegido, o bien sobre subconjuntos del mismo definidos dinámicamente de acuerdo con las necesidades específicas. Veamos las diversas posibilidades:
La casilla [Medio] discrimina los textos del corpus de acuerdo con su procedencia: libros, periódicos, revistas, miscelánea y orales.
Limita la consulta a un autor determinado. Para ello, basta con escribir en la casilla [Autor] el apellido/apellidos del autor. Ej.: Lope para seleccionar las obras de Lope de Vega.
Especifique una o más palabras significativas en la casilla [Título] exactamente como aparecen en el título de la obra deseada. Ej.: Quijote para limitar la consulta a la célebre obra de Cervantes.
El apartado [Cronológico] dispone de dos casillas que permiten la selección de un año concreto (Primera casilla) o bien del período comprendido entre dos fechas. Ej.: 1990 seleccionará exclusivamente las obras del año 1990. 1990 - 1998 obtendrá las obras comprendidas en ese período.
La ventana de selección de [Tema] ofrece la posibilidad de delimitar una o varias áreas temáticas y/o temas de acuerdo con las divisiones previamente fijadas en el diseño del corpus. La ausencia de selección equivale a seleccionar el corpus completo.
Mediante la ventana de selección de criterio [Geográfico] es posible filtrar las consultas restringiendo los materiales a uno o varios países. La ausencia de criterios restrictivos equivale a seleccionar todos los países.
3.4 SINTAXIS DEL LENGUAJE DE CONSULTA.
Existen dos métodos para formular las consultas, el primero consiste en utilizar palabras del "lenguaje natural", mientras que el segundo está basado en la composición de expresiones lógicas. El apartado [Consulta] es el destinado a contener la palabra o expresión que se desea analizar. Puede contener formas de palabras completas, abreviadas (prefijos, sufijos...), grupos de palabras o bien expresiones lógicas.
Existen algunas normas de carácter general que conviene tener en cuenta:
La manera más sencilla de realizar una consulta consiste en escribir la palabra o secuencia de palabras deseadas. Utilice para ello el apartado [Consulta]. Por ejemplo, perro, perro del hortelano etc.
Una palabra o secuencia de palabras no siempre proporcionan la información adecuada. Para paliar ese problema, existen expresiones lógicas consistentes en grupos de palabras o frases relacionadas entre sí mediante el empleo de los operadores lógicos Y, O, NO y del operador de distancia DIST/. Veamos algunos ejemplos ilustrativos de la manera de formular dichas consultas:
manzana Y pera (Las dos palabras deben estar presentes en el documento).
manzana O pera (Al menos una de las palabras debe de estar presente en el documento)
manzana dist/5 pera (La palabra manzana debe de aparecer a una distancia medida en palabras no superior a 5 de la palabra pera)
manzana NO dist/5 pera (La palabra manzana no debe aparecer a una distancia inferior a 5 palabras de la palabra pera)
manzana Y NO pera ( Únicamente debe aparecer la palabra manzana en el documento)
Es posible ampliar o concretar la búsqueda incluyendo los signos "?" y "*" como "comodines" en la formación de las palabras. La interrogación cerrada (?) sustituye a un carácter en una posición determinada, mientras que el asterisco (*) sustituye a cualquier número de caracteres. Por ejemplo, la consulta Pedr* producirá: Pedro, Pedrito, Pedrada, etc., M?sa resolverá: Mesa, Masa, Misa, Musa.
El sistema de filtros tiene por objeto obtener una reducción del número de ejemplos cuando la abundancia de los mismos obstaculiza la labor de consulta. Su aplicación se realiza mediante la selección de la casilla correspondiente en el apartado [Filtros]. Existen dos tipos de filtros que se ocupan de reducir el número de documentos o ejemplos proporcionados en una consulta, minimizando la pérdida de representatividad de los datos obtenidos.
3.4.6 Reducción del número de documentos.
La misión del filtro [Documentos] consiste en disminuir en la proporción elegida el número de documentos obtenidos en la consulta. Su aplicación dará lugar a un nuevo perfil de consulta cuyo contenido será el resultado de seleccionar los documentos alternativamente. De ese modo, un filtro de tipo 1/2 seleccionará los documentos 1, 3, 5, 7, 9... del conjunto inicial.
3.4.7 Reducción del número de ejemplos.
El filtro [Casos] tiene por objeto reducir el número de ejemplos que se ofrecen en cada documento. De esta forma, si un documento contiene 10 ejemplos de la consulta realizada, la aplicación de este filtro en la proporción 1/2 reduce a 5 los casos seleccionando alternativamente un caso de cada dos. El botón [Mantener documentos] tiene la misión de mantener el criterio de representatividad. Para lograrlo, conserva como mínimo un ejemplo de cada uno de los documentos inicialmente seleccionados.
4. Visualización y clasificación de los ejemplos.
Una vez efectuada una consulta, es posible recuperar la relación de autores y obras, los ejemplos, así como realizar diversas clasificaciones, cuadros estadísticos, etc.
El apartado denominado [Obtención de ejemplos] muestra mediante la selección del perfil [Recuperar: Documentos] una relación de los documentos que contienen ejemplos relativos al perfil de consulta activo. El apartado [Clasificación] determina el tipo de clasificación de acuerdo con los criterios de relevancia (número de casos que contiene el documento), autor, fecha, país, clasificación temática o título de la obra. Por defecto, el criterio de clasificación es el de relevancia. La descripción bibliográfica de cada documento muestra de forma tabular la información relativa al número de ejemplos, título del documento, autor, año de la 1ª edición, país y área temática.
La selección del apartado [Recuperar: Concordancias] muestra los ejemplos (concordancias) de la consulta activa. Los ejemplos de la palabra o expresión consultada se muestran en formato tabular centrados en su contexto. En la zona derecha de cada ejemplo, es posible obtener una descripción bibliográfica mediante el desplazamiento del cursor sobre la barra horizontal; alternativamente, una pulsación sobre la zona subrayada de la línea deseada mostrará en una ventana independiente el ejemplo ampliado, así como la descripción bibliográfica completa del documento que lo contiene.
El apartado [Clasificación] recoge diversos criterios de ordenación de ejemplos. Es posible recuperar los ejemplos ordenados por los criterios de relevancia (número de casos que contiene el documento), autor, fecha, país, clasificación temática o título de la obra.
Existe un segundo apartado de clasificación por contexto, que facilita la clasificación de los ejemplos de acuerdo con sus contextos morfológicos. Una clasificación del tipo Izda(1) significa que los ejemplos son ordenados de acuerdo con la primera palabra que aparece a la izquierda del ejemplo. La selección Dcha(3) clasifica los ejemplos por las tres primeras palabras posteriores al ejemplo. La clasificación por Pivote muestra los ejemplos ordenados alfabéticamente de acuerdo con las variantes generadas por la expresión consultada. Tiene sentido en consultas que contienen comodines o expresiones lógicas.
La selección combinada de los criterios temáticos y contextuales produce como resultado una lista de ejemplos doblemente clasificada en la que el orden primario viene determinado por el criterio temático.
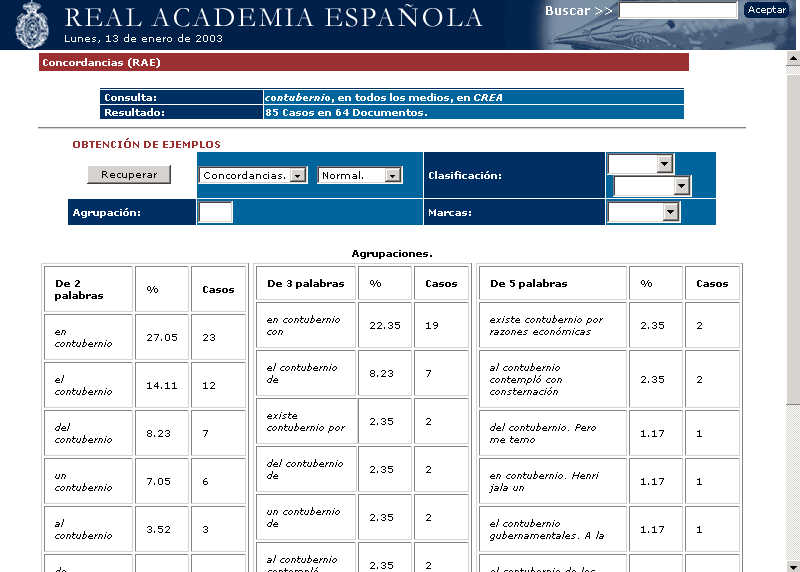
A menudo resulta útil obtener una visión sumaria (colocaciones) de los patrones más frecuentes para una palabra. La opción [Recuperar: Agrupaciones] ofrece un resumen de los rasgos contextuales que acompañan a una palabra o expresión. El apartado [Agrupa] permite especificar el número de palabras que intervendrán en la confección del sumario. El sistema ofrecerá por defecto las agrupaciones correspondientes a contextos de 2,3 y 5 palabras.
El filtro contextual (si existe) indicará a su vez, la palabra de referencia para extraer los contextos más frecuentes; en principio se tomará como referencia la palabra consultada. Eje. el filtro contextual [Izda(1)], supondrá la realización de agrupaciones basadas en la palabra inmediatamente anterior en el contexto a la consultada.
Fig 2. Agrupaciones más frecuentes.
4.2.3 Selección manual de ejemplos.
En ocasiones, es conveniente seleccionar los ejemplos correspondientes a ciertos documentos de la lista de autores y obras. La activación del apartado [Selección] proporciona esa posibilidad, mostrando únicamente los ejemplos de las obras previamente seleccionadas de forma manual en la ventana [Documentos].
4.2.4 Visualización de la información codificada.
Los corpus CREA y CORDE contienen abundante información codificada que identifica aspectos del texto que requieren un tratamiento especial. Normalmente, la información que proporciona la codificación es útil únicamente para los especialistas. Sin embargo, existe la posibilidad de mostrar el texto codificado mediante el apartado [Marcas]. Por ejemplo, si efectúa una consulta sobre transcripciones de conversaciones (apartado "Oral"), y selecciona el apartado [Marcas: Oral], podrá ver las concordancias o los párrafos con la codificación relativa al hablante, tipo de conversación etc.
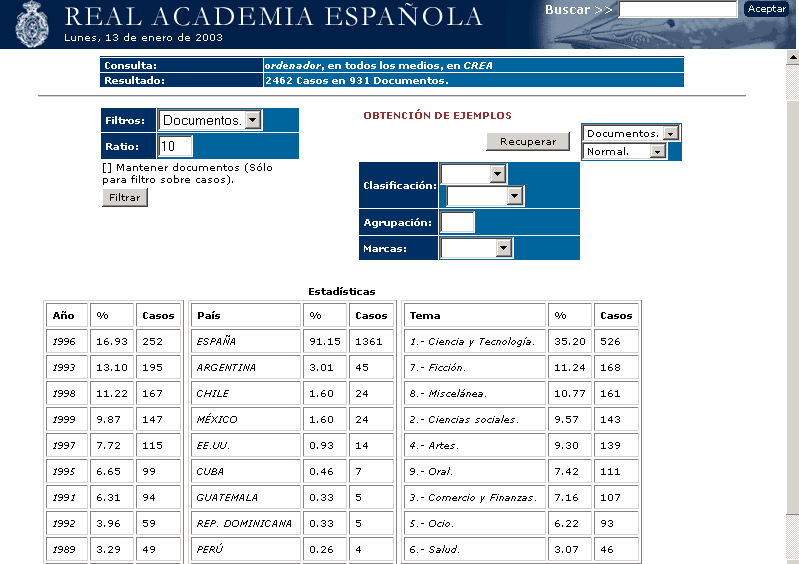
5. Presentación estadística de los datos.
El apartado denominado [Estadísticas] muestra algunos datos estadísticos básicos correspondientes a la última consulta efectuada. Ofrece una panorámica rápida, útil para discernir el ámbito de aparición, los sesgos temáticos o la distribución cronológica de los ejemplos obtenidos. Mediante el empleo de tablas se muestra el número de casos y los porcentajes absolutos de los casos obtenidos, clasificados por criterios temáticos, cronológicos y geográficos.
Fig. 2. Distribución porcentual absoluta de los datos.
6. Exportación e impresión de los resultados de las consultas.
La salvaguardia e impresión de los datos se realiza a través de las facilidades que proporciona el navegador WWW. Por lo tanto, cualquier información obtenida en la pantalla es susceptible de exportación. Por ejemplo, la relación de autores y obras, o bien los ejemplos en formato reducido y ampliado. En todos los casos se obtienen los datos en formato HTML, listos para su publicación en el WWW, o el intercambio con los principales sistemas de tratamiento de textos.
Siga las instrucciones en secuencia (recuerde que puede obviar las identificadas como {opcional}.
a)
Teclee la palabra, secuencia de palabras o expresión lógica que desea consultar en el apartado [Consulta]. Tenga en cuenta que el sistema distingue entre mayúsculas y minúsculas y signos diacríticos. Escriba, por ejemplo, la expresión: amor platónico.b)
Pulse la tecla [Buscar] situada en el extremo inferior izquierdo de la ventana de consulta. En circunstancias normales, el sistema responderá en cuestión de segundos, mostrando en la ventana denominada [Resultados] una línea o perfil de consulta, que le informará del número de ejemplos obtenidos, de los documentos relacionados con la consulta, del corpus utilizado y de las áreas temáticas seleccionadas.
c)
En el apartado [Obtención de ejemplos] seleccione la opción [Concordancias] y pulse el botón [Recuperar]. Obtendrá los ejemplos correspondientes a la consulta efectuada. Las opciones del apartado [Clasificación] le permitirá ordenar los ejemplos atendiendo a criterios temáticos o contextuales. Por ejemplo, el criterio [Casos] ordena los ejemplos de acuerdo con su relevancia (aparecerán primero los ejemplos correspondientes a las obras que tienen mayor número de casos de la palabra o expresión solicitada).8. Limitaciones y problemas conocidos.
El sistema de consulta tiene algunas limitaciones, impuestas en algunos casos por las propias herramientas informáticas o establecidas convencionalmente por el equipo responsable del diseño, con el único objeto de preservar la disponibilidad del sistema y, con ella, los intereses de la mayoría de los usuarios.
Como norma general, las consultas que sobrepasen los límites anteriores deben ser replanteadas recurriendo a los criterios de selección o a los filtros disponibles.
El mensaje se produce generalmente por saturación de la red, del servidor o bien por la interrupción temporal del servicio. En ocasiones, las consultas demasiados complejas ocasionan la pérdida de comunicación por tiempo de espera. En ese caso, es conveniente recurrir a la segmentación o reducción de la consulta mediante la utilización de los filtros.
Situación producida por la excesiva complejidad de una consulta. Generalmente es debida al uso indiscriminado de prefijos, sufijos o expresiones lógicas que generan gran número de variantes (más de 500).
El sistema de consulta continúa en desarrollo. Las principales novedades que serán incluidas en sucesivas versiones del programa son las siguientes:
Nuevos filtros estadísticos.
Recuperación sobre textos anotados con información lingüística. ( lema, clase de palabra, género, número etc.).
Salvaguardia de los perfiles de consulta.
En un sistema en desarrollo es importante obtener la opinión de los usuarios para mejorar el servicio. Por ese motivo, está disponible una dirección de correo electrónico
dbd@rae.es que pretende recoger consultas y sugerencias.
REAL ACADEMIA ESPAÑOLA: Banco de datos (CORDE) [en línea]. Corpus diacrónico del español. <https://www.rae.es> [Fecha de la consulta]
REAL ACADEMIA ESPAÑOLA: Banco de datos (CREA) [en línea]. Corpus de referencia del español actual. <https://www.rae.es> [Fecha de la consulta]
Apéndice 1. Diseño y estructura del Banco de Datos del Español.
El banco de datos del español está dividido en dos grandes conjuntos documentales: CREA y CORDE. El CREA (Corpus de Referencia del Español Actual) contiene ejemplos de los últimos 25 años del idioma. El CORDE (Corpus Diacrónico del Español) abarca ejemplos desde los orígenes del español hasta el limite cronológico con el CREA.
A1.1 DISEÑO DEL CORPUS DEL REFERENCIA DEL ESPAÑOL ACTUAL. CREA.
El diseño del Corpus de Referencia del Español Actual (CREA) responde a la intención de ofrecer a los investigadores de esta lengua y a los interesados en ella una muestra representativa y equilibrada del español estándar que se utiliza actualmente en el mundo. Con el fin de permitir la mayor flexibilidad posible en la obtención de datos, el CREA está estructurado en diferentes módulos, lo cual hará posible que las consultas vayan referidas a la totalidad de los textos o bien únicamente a aquellos que poseen unas determinadas características geográficas, temáticas, temporales, etc.
Esa estructura compleja se consigue a base de cruzar una serie de criterios diversos, cuya reunión traza la configuración general del CREA:
Cronológicos: los últimos veinticinco años (1975-1999).
Geográficos: textos españoles y americanos distribuidos al 50%.
Medio: textos publicados en libros, revistas, periódicos, transcripción oral.
Temáticos: ciencia, política, vida cotidiana, economía, ficción, etc.
Buscando el equilibrio entre la obtención de la mayor cantidad posible de formas y la posibilidad de enriquecer el corpus mediante codificación y anotación gramatical, el tamaño del CREA al final de su segunda fase (diciembre del año 2000) será de 125 millones de formas. El 90% de esa cantidad procederá de textos escritos y el 10%, de textos orales. Dado que el tamaño previsto para el corpus parece garantizar la variedad y representatividad del conjunto, se ha optado por introducir en el CREA los textos completos en todos los casos.
Los rasgos generales de la distribución de textos son los siguientes:
|
España: 50% |
|
Escritos: 90% |
|
Orales: 10% |
|
Distribución temporal de los textos del CREA |
|
|
1975-1979 |
10% |
|
1980-1984 |
15% |
|
1985-1989 |
20% |
|
1990-1994 |
25% |
|
1995-1999 |
30% |
|
Distribución de los textos del CREA por grandes áreas temáticas (hipercampos) (porcentajes sobre el total) |
|
|
1. Ciencia y Tecnología |
10,125% |
|
2. Ciencias sociales, creencias, pensamiento |
13,5% |
|
3. Política y Economía |
13,5% |
|
4. Artes |
10,125% |
|
5. Ocio y vida cotidiana |
10,125% |
|
6. Salud |
10,125% |
|
7. Ficción |
22,5% |
En los textos procedentes de América, se ha intentado reflejar la diversidad existente mediante el reconocimiento de diversas áreas lingüísticas, a cada una de las cuales se ha asignado un porcentaje diferente en función de su población y peso cultural:
|
|
Porcentaje sobre la parte americana del CREA |
Países o zonas |
|
Zona mexicana |
40% |
México, Sudoeste de Estados Unidos, Guatemala, Honduras, El Salvador |
|
Zona central |
3% |
Nicaragua y Costa Rica |
|
Zona caribeña |
17% |
Cuba, Puerto Rico, Panamá, Rep. Dominicana, Costas de Venezuela y Colombia y Nordeste de Estados Unidos |
|
Zona andina |
20% |
Resto de Venezuela y Colombia, Ecuador, Perú y Bolivia |
|
Zona chilena |
6% |
Chile |
|
Zona rioplatense |
14% |
Argentina, Paraguay y Uruguay |
Con el permiso de sus responsables, han pasado a formar parte del CREA textos procedentes de otros corpus de español, que, en todos los casos, han sido sometidos al esquema de codificación propio del CREA. En este momento están ya integrados textos procedentes de los corpus siguientes:
Entrevis
Corpus oral de referencia del español
Proyecto Dies-RTV
A1.2 DISEÑO DEL CORPUS DIACRÓNICO DEL ESPAÑOL. CORDE.
El Corpus Diacrónico del Español (CORDE) pretende recoger un conjunto de 125.000.000 de palabras que abarquen desde los inicios del idioma hasta el año 1975, en que limita con el CREA que también elabora la Academia. Se trata de un corpus escrito, de texto completo, que como su hermano CREA utiliza una marcación mínima según el sistema SGML (Standard Generalized Markup Language). Su propósito es permitir al consultante una gran versatilidad en lo que se refiere a la explotación, para lo cual CORDE se ha estructurado teniendo en cuenta diversos parámetros, como los siguientes:
-cronológicos: El Corpus se divide en tres grandes etapas (Edad Media, Siglos de Oro y Época Contemporánea), que a su vez se pueden agrupar en períodos menores según criterios histórico-lingüísticos.
-geográficos: CORDE recoge el español de todas las partes del mundo en que se habla o se habló. Dada su perspectiva diacrónica, otorga un peso del 74% para el español peninsular y un 26% para el resto.
-de modalidad y género: El corpus se divide en dos grandes grupos:
1. Ficción, compuesto por textos de Verso y Prosa, a su vez subdivididas en Lírico, Épico, Dramático, y
2. No ficción, donde aparece Prosa estructurada en didáctica, científica, de sociedad, de prensa y publicidad, religiosa, histórico-documental y jurídica.
El CORDE pretende servir tanto a un investigador interesado en la existencia de una palabra o expresión o que quiera llevar a cabo un estudio gramatical, como a los lexicógrafos que con sus materiales elaboren el Diccionario histórico.
Aunque está previsto que CORDE y CREA se complementen y los textos del segundo vayan pasando al primero a medida que vaya ampliando su techo de años, también existen diferencias entre ambos corpus, dada la particular idiosincrasia de CORDE y el carácter de los textos que incorpora (verso, textos anotados, textos con preliminares y otras composiciones ajenas a la obra en sí). De ahí que CORDE haya adaptado un sistema de marcación que le permite identificar en sus textos -mediante las marcas correspondientes- los versos (su estructuración partida, si es el caso), los textos ajenos, los textos en lengua extranjera, las notas al texto (cuya huella queda para advertir al consultante que una palabra o expresión ha merecido un estudio particular), etc.
Distribución genérica
|
Ficción (verso, prosa, teatro): |
44% |
|
No ficción: |
56% |
|
Didáctica: |
9% |
|
Ciencia y Técnica: |
15% |
|
Sociedad (y prensa y public.) |
8% |
|
Religión: |
6% |
|
Historia: |
13% |
|
Derecho y C. Jurídica: |
5% |
Distribución cronológica.
|
EDAD MEDIA |
21% |
|
1. Orígenes hasta c1250. |
|
|
2. 1250-1492. |
|
|
SIGLOS DE ORO |
28% |
|
1. 1493 -1598. |
|
|
2. 1599-1713. |
|
|
ÉPOCA CONTEMPORÁNEA |
51% |
|
1. 1714-1812. |
|
|
2. 1813-1898. |
|
|
3. 1899-1936. |
|
|
4. 1937-1974. |
Cuadro resumen.
|
GÉNEROS |
E. MEDIA |
S. DE ORO |
CONTEMP. |
TOTAL |
% |
|
VERSO lírico |
2 000 000 |
2 500 000 |
3 000 000 |
7 500 000 |
6% |
|
V épico |
3 250 000 |
1 000 000 |
750 000 |
5 000 000 |
4% |
|
V dramático |
750 000 |
2 812 500 |
1 625 000 |
5 187 500 |
4,15% |
|
PROSA lírica |
- |
- |
500 000 |
500 000 |
0,4% |
|
P narrativa |
3 125 000 |
8 750 000 |
19 562 500 |
31 437 500 |
25,15% |
|
P dramática |
250 000 |
1 250 000 |
3 375 000 |
4 875 000 |
3,9% |
|
P didáctica |
2 125 000 |
2 625 000 |
6 625 000 |
11 375 000 |
9,1% |
|
P científica |
4 200 000 |
4 637 500 |
9 537 500 |
18 375 000 |
14,7% |
|
P de sociedad- |
2 250 000 |
2 875 000 |
5 000 000 |
10 125 000 |
8,1% |
|
Period-public |
- |
375 000 |
3 000 000 |
3 375 000 |
2,7% |
|
P religiosa |
2 500 000 |
2 250 000 |
2 875 000 |
7 625 000 |
6,1% |
|
P histórica |
3 500 000 |
4 625 000 |
8 125 000 |
16 250 000 |
1,3% |
|
P jurídica |
2 000 000 |
1 750 000 |
3 000 000 |
6 750 000 |
5,4% |
|
TOTALES |
25 950 000 |
35 075 000 |
63 975 000 |
125 000 000 |
100% |
____ ____ ____